School of Electrical Engineering and Computer Science (EECS) researchers recently presented a paper at the prestigious Neural Information Processing Systems (NeurIPS2024) conference.
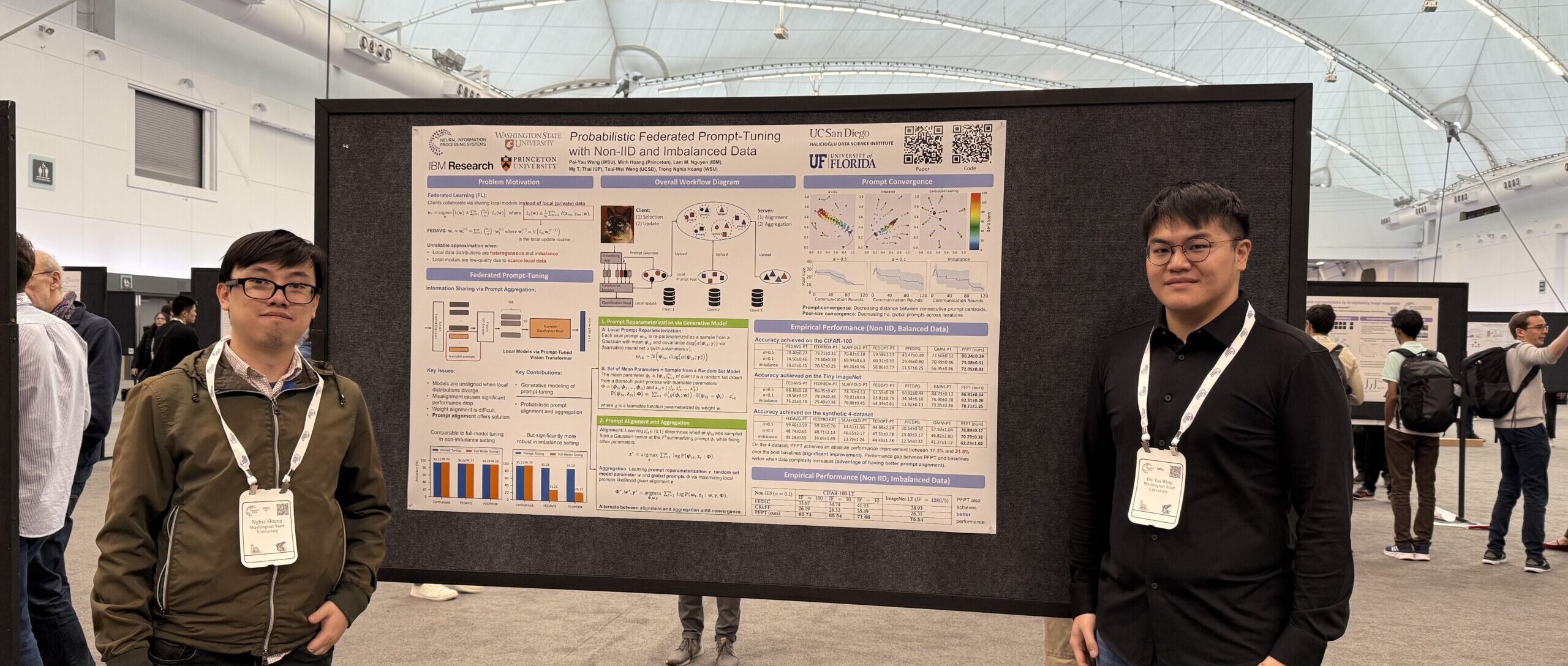
Led by graduate student Pei-yau Weng and Assistant Professor Trong Nghia Hoang, the WSU team presented on Probabilistic Federated Prompt-Tuning in Data Imbalance Settings. In addition to Hoang, researchers on the work included Minh Hoang from Princeton, Lam Nguyen from IBM, My Thai, from University of Florida, and Lily Weng, from University of California, San Diego.
The multidisciplinary, international conference brings together a wide variety of researchers from wide-ranging fields of study, including in artificial intelligence and machine learning as well as from neuroscience, life sciences, natural sciences, and social sciences. With growing worldwide interest in AI research and development, the conference, held in Vancouver, B.C. in December, had more than 16,000 attendees.
Hoang also recently presented on Collaborative Learning across Heterogeneous Systems with Pre-Trained Models as a new faculty highlight at the Association for the Advancement of Artificial Intelligence.
Abstract:
Probabilistic Federated Prompt-Tuning in Data Imbalance Settings.
Fine-tuning pre-trained models is a popular approach in machine learning for solving complex tasks with moderate data. However, fine-tuning the entire pre-trained model is ineffective in federated data scenarios where local data distributions are diversely skewed.
To address this, we explore integrating federated learning with a more effective prompt-tuning method, optimizing for a small set of input prefixes to reprogram the pre-trained model’s behavior. Our approach transforms federated learning into a distributed set modeling task, aggregating diverse sets of prompts to globally fine-tune the pre-trained model. We benchmark various baselines based on direct adaptations of existing federated model aggregation techniques and introduce a new probabilistic prompt aggregation method that substantially outperforms these baselines.
Our reported results on a variety of computer vision datasets confirm that the proposed method is highly effective to combat extreme data heterogeneity in federated learning.